Apache Gravitino 0.9.0 - Focus on AI, data governance, and security with multi-dimensional feature upgrade

Gravitino 0.9.0 focuses on advancements in AI, data governance, and security. Many of its new features are already being used in production environments. The release has attracted strong interest from users from well-known companies, with AI and security capabilities drawing attention.
In this version, the community optimized the user experience for fileset catalogs and model catalogs, making it easier for users to manage their unstructured AI data and model data.
The community added a new data lineage interface. Users can now implement a custom data lineage plugin to adapt to their own system.
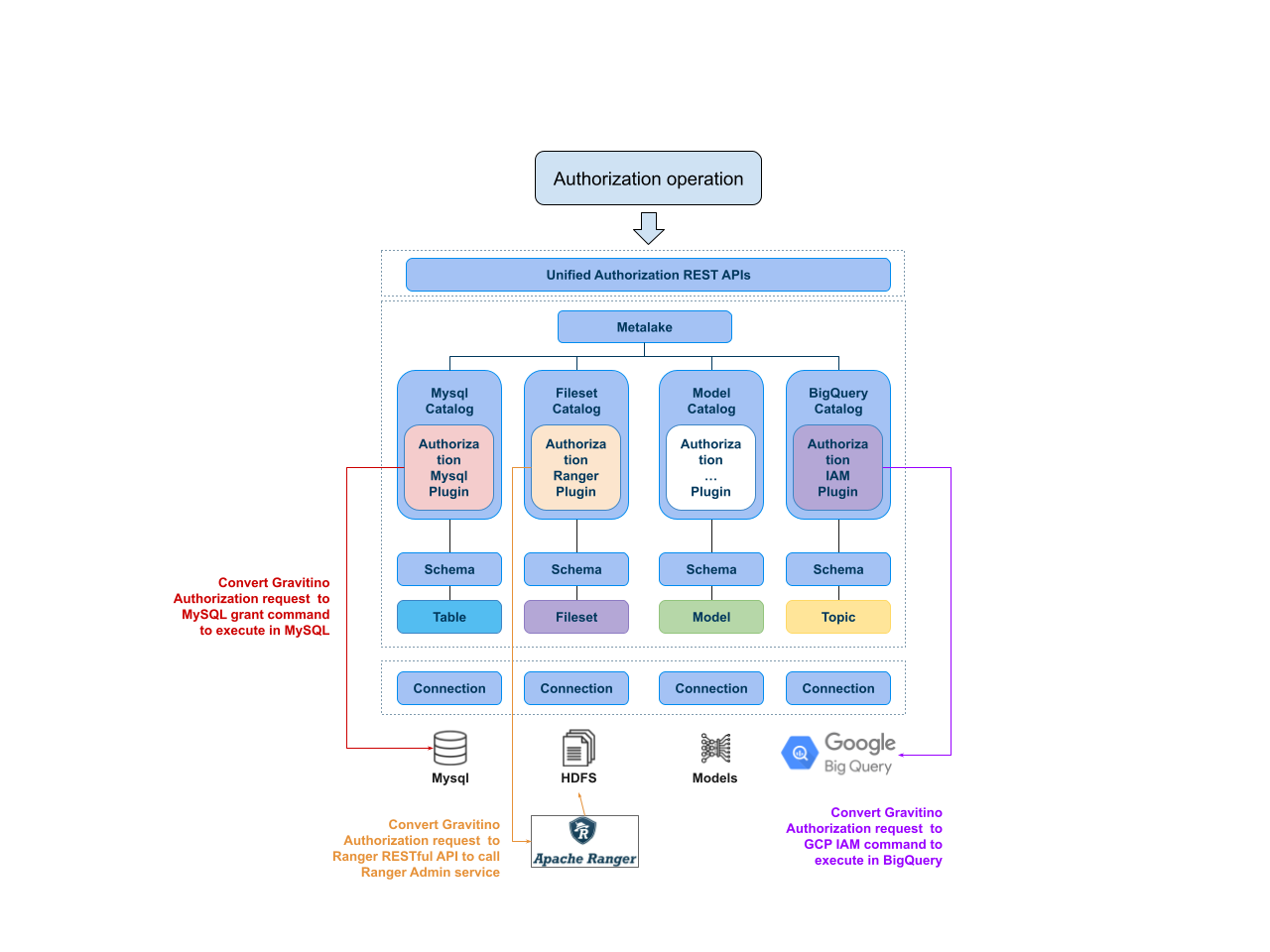
For security, the community has corrected some privilege semantics and fixed authorization plugin corner cases to make the entire system more robust.
Model Catalog
Before 0.9.0, the model catalog was immutable, which was not flexible. In the new version, users can alter models and model versions and add tags #6626 #6222.
Fileset Catalog
Gravitino now supports multiple named storage locations within a single fileset and placeholder-based path generation.
With multiple location support, users can reference data across different file systems (HDFS, S3, GCS, local, etc.) through a unified fileset interface, each with a unique location name.
The placeholder feature allows dynamic storage path generation using the {{placeholder}} syntax, automatically replacing placeholders with corresponding fileset properties.
These enhancements significantly improves the flexibility for multi-cloud environments and complex data organization patterns while maintaining a clean abstraction layer for data assets management #6681.
GVFS (Gravitino Virtual File System)
GVFS has been enhanced to support accessing multiple locations within filesets. Users can now select which location to use through configuration properties, environment variables, or fileset default settings.
GVFS has also been refactored with a pluggable architecture allowing custom operations and hooks. This enables users to extend functionality through operations_class and hook_class configuration options for more flexible integration with their specific infrastructure #6938.
Security
The new version has added privileges for the data model and corrected some privilege semantics. It has also fixed some bugs with the Ranger path-based plugin #6620 #6575 #6821 #6864. All of the user-related, group-related, and role-related events are now supported for the event system #2969.
Data Lineage
The community added a data lineage interface that follows the OpenLineage API specification. Users can implement their custom data lineage plugin to adapt to their system #6617.
Core
The community cared about performance. Performance was improved by reducing the scope of the lock and batch reading data from storage #6744 #6560 #2870.
CLI
Additionally, there is one more change worth mentioning. Users no longer need to rely on the alias command to use the CLI. Instead, the community provided a convenient script located at ./bin/gcli.sh so that a user can directly use the CLI client #5383.
Connector
Both the Flink connector and the Spark connector added JDBC support #6233 #6164.
Chart
Deploying Gravitino on Kubernetes with a fully customizable configuration #6594.
Overall
Gravitino 0.9.0 focuses on advancements in AI, data governance, and security. We thank the Gravitino community for their continued support and valuable contributions. We can continue to innovate and build thanks to all our users' feedback. Thank you for taking the time to read this! To dive deeper into the Gravitino 0.9.0 release, explore the full documentation. Your feedback is greatly valued and helps shape the future of the Gravitino project and community.
Credits
JavedAbdullah AndreVale69 Brijeshthummar02 cool9850311 liuchunhao danhuawang unknowntpo FANNG1 tsungchih jerryshao justinmclean zhoukangcn Abyss-lord amazingLyche yuqi1129 Pranaykarvi puchengy LauraXia123 tengqm rud9192 antony0016 frankvicky TEOTEO520 TungYuChiang sunxiaojian xunliu LuciferYang diqiu50 zhengkezhou1 caican00 granewang yunchipang jerqi mchades rickyma Xander-run flaming-archer waukin lsyulong luoshipeng FourFriends this-user vitamin43 hdygxsj liangyouze
Apache, Apache Fink, Apache Hive, Apache Hudi, Apache Iceberg, Apache Ranger, Apache Spark, Apache Paimon and Apache Gravitino are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.